네트워크를 생성하고 테스트데이터와 대조를 해본결과 과대적합이 일어나는 것을 볼 수 있었습니다.
과대적합이 일어나는 이유는 다음과 같습니다.
첫째로, 데이터셋이 옳지 못할때 발생합니다. 올바른 데이터가 입력되면 출력또한 올바르지못한 데이터가 될 것입니다.
이경우에는 데이터셋의 잘못된 부분을 수정하여 올바른 데이터 출력을 끌어 낼 수 있습니다
둘째는 데이터 입력값이 너무 많거나 적을 때 발생합니다. 이번 개와 고양이의 이미지를 분류할때 데이터 값이 적어서 과대적합이
일어난 것으로 보여집니다. 때문에 데이터를 증식하는 방법을 이용하여 과대적합을 잡아보겠습니다.
우선 사진증식이 잘되는지 테스트를 먼저 수행하겠습니다.
fnames = sorted([os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)])
# 증식할 이미지 선택합니다
img_path = fnames[1]
# 이미지를 읽고 크기를 변경합니다
img = image.load_img(img_path, target_size=(150, 150))
# (150, 150, 3) 크기의 넘파이 배열로 변환합니다
x = image.img_to_array(img)
# (1, 150, 150, 3) 크기로 변환합니다
x = x.reshape((1,) + x.shape)
# flow() 메서드는 랜덤하게 변환된 이미지의 배치를 생성합니다.
# 무한 반복되는 루프이기 때문에 중단이 필요하다.
i = 0
for batch in datagen.flow(x, batch_size=1):
plt.figure(i)
imgplot = plt.imshow(image.array_to_img(batch[0]))
i += 1
if i % 4 == 0:
break
plt.show()이렇게 코드를 입력해주면 사진이 출력이됩니다

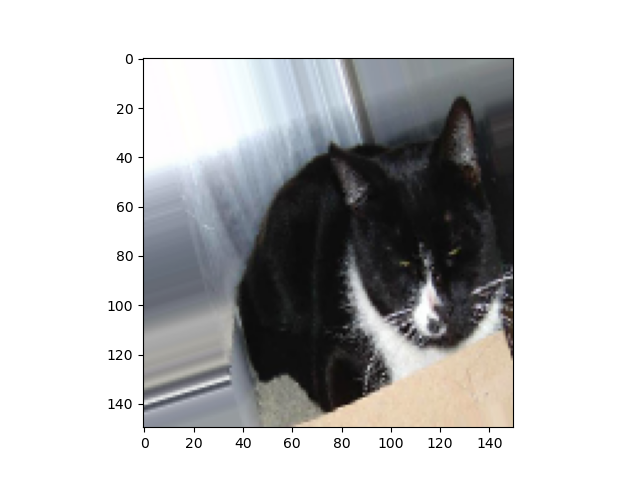

원본이미지와 위치,회전,크기를 변경시킨 여러 사진들이 증식됨을 볼수있습니다.
증식이 되는것을 테스트 완료했으니 이제 실제 데이터에 적용을 해보겠습니다.
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,)사진을 증식 시킬 옵션을 설정해 줍니다. 각 매서드의 설명은 다음과 같습니다
# rotation_range = 사진을 회전시킴
# width_shift_range와 height_shift_range는 사진을 수평과 수직으로 랜덤하게 평행 이동시킬 범위의 비율
# share range = 랜덤하게 전단 변환을 할 각도
# zoom range = 랜덤하게 화면을 확대할 범위
# horizen_flip = 랜덤하게 이미지를 수평으로 뒤집음
# fill mode = 회전이나, 가로세로 이동으로인해 픽셀을 채워야하는경우
매서드 설정을 마친후에 데이터셋을 증식시켜줍니다. 이때주의할점은 검증용데이터에는 절대로 증식을 하면 안됩니다.
# 검증 데이터는 증식되어서는 안 됩니다!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
model_f2 = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=100,
validation_data=validation_generator,
validation_steps=50)
데이터의 증식도 맞췄고 에포크당횟수도 50회에서 100회로 늘려서 테스트를 진행하도록 하겠습니다.
이제 결과를 시각화하여 확인해 보도록 하겠습니다.
acc = model_f2.history['acc']
val_acc = model_f2.history['val_acc']
loss = model_f2.history['loss']
val_loss = model_f2.history['val_loss']
epochs = range(len(acc))
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.legend()
plt.figure()
plt.plot(epochs, loss, 'bo', label='Training loss')
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.legend()
plt.show()
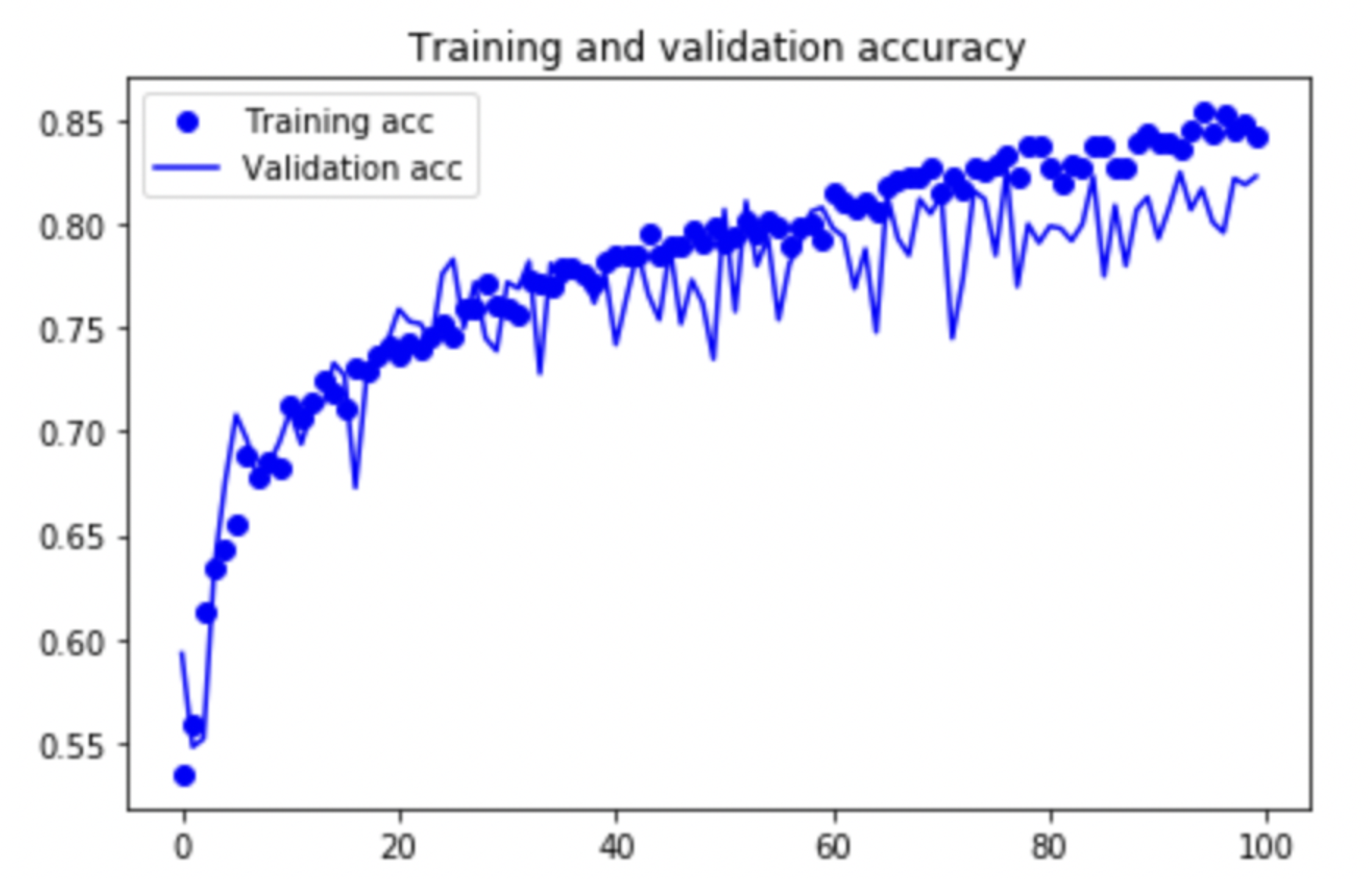

데이터를 증식하고 에포크당 스텝수를 늘려주었더니 과대적합(overfitting) 현상이 확연하게 좋아진것을 볼수있습니다.
이상 Keras패키지를이용하여 네트워크를 생성하고, 부족한 데이터양을 채우기위해 증식을 하는 포스팅을 마무리하겠습니다.
'Python > Keras' 카테고리의 다른 글
| [P]Keras 패키지를 이용하여 개와 고양이 이미지 분류하기 -2- (0) | 2022.02.22 |
|---|---|
| [P]Keras 패키지를 이용하여 개와 고양이 이미지 분류하기 -1- (0) | 2022.02.21 |

