[R] R을 이용하여 감정분석하기 -1-
최근에 비정형데이터가 많이 증가함에 따라서 사람들이 반응을 확인하고 마케팅에 이용하기 위해 감정분석을 많이 이용합니다.
감정분석은 긍정어,부정어,중립어를 구분하여 점수를 매겨 진행하게 됩니다.
감정분석을위해 KNU 감성 사전을 이용 하였습니다.
KNU 한국어 감성사전 출처: github.com/park1200656/KnuSentiLex
install.packages("tidyverse")
library(tidyverse)
install.packages('knitr')
library(knitr)
install.packages('dplyr', type = 'binary') # 감정사전 불러오기 패키지
library(dplyr)
install.packages('readr') # 감정사전 불러오기 패키지
library(readr)
install.packages('stringr')
library(stringr)
install.packages('tidytext')
library(tidytext)
install.packages('textclean')
library(textclean)감정분석을 이용하기위하여 위와 같은 패키지들을 설치하고 라이브러리 해주어야 합니다.
다음 감정분석을 위하여 사전을 불러오도록 하겠습니다.
getwd()
setwd('/Users/sik/Desktop/dataset5')
dic <- read_csv("knu_sentiment_lexicon.csv")
dicread_csv를 이용하면 read.csv보다 더 빠르게 데이터를 가져 올 수 있습니다.
dic라는 변수에 사전을 저장하였으니 데이터가 잘 들어갔는지 확인해 보도록 하겠습니다.
# 긍정단어
dic %>% filter(polarity == 2) %>% arrange(word)
# 부정단어
dic %>% filter(polarity == -2) %>% arrange(word)코드를 위처럼 입력해 줍니다.
여기서 word는 한단어, 여러단위로 이루어진 복합어나 이모티콘을 포함 하고있습니다.
polarity는 (-2,-1,0,1,2)의 정수로 이루어져 있으며 2로 가까워질수록 긍정적단어, -2로 가까워질수록 부정적인 단어로 해석 될 수 있습니다.
이제 결과 값을 확인해보도록 하겠습니다.
> dic %>% filter(polarity == 2) %>% arrange(word)
word polarity
1 가능성이 늘어나다 2
2 가능성이 있다고 2
3 가능하다 2
4 가볍고 상쾌하다 2
5 가볍고 상쾌한 2
6 가볍고 시원하게 22에해당하는 긍정어들만 보여줌을 알 수 있습니다.
감정사전에 얼만큼의 감성어가 들어있는지 확인해 보도록 하겠습니다.
dic %>% mutate(sentiment = ifelse(polarity >= 1, 'pos',
ifelse(polarity <= -1, 'neg', 'neu'))) %>% count(sentiment)위코드는 1과 같거나 1보다 크면 'pos'(긍정어), -1 이거나 그보다 작으면 'neg'(부정어), 그외 숫자인 0은'neu'(중립어)로 분류하여 카운팅 해줍니다.
결과를 확인해 보도록 하겠습니다.
> dic %>% mutate(sentiment = ifelse(polarity >= 1, 'pos',
+ ifelse(polarity <= -1, 'neg', 'neu'))) %>% count(sentiment)
# A tibble: 3 × 2
sentiment n
<chr> <int>
1 neg 9829
2 neu 154
3 pos 4871총 14,854단어가 들어있는 감성 사전입니다.
이제 사전을 불러왔으니 크롤링된 기사의 댓글을 분석 해보도록 하겠습니다.
사용할 데이터는 기생충 기사에대한 댓글입니다.
우선 기사에 달린 댓글들을 변수에 저장해 줍니다.
raw_news_comment <- read_csv('news_comment_parasite.csv')# 기본적 전처리
news_comment <- raw_news_comment %>% mutate(id = row_number(),
reply = str_squish(replace_html(reply)))
# 데이터 구조 확인
glimpse(news_comment)저장된 기사의 댓글에 숫자를 달고 양쪽의 여백을 정리해줍니다.
그뒤 데이터의 구조를 확인해 보도록 하겠습니다.
> glimpse(news_comment)
Rows: 4,150
Columns: 6
$ reg_time <dttm> 2020-02-10 16:59:02, 2020-02-10 13:32:24, 2020-02-10 12:30:09, 2020…
$ reply <chr> "정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 …
$ press <chr> "MBC", "SBS", "한겨레", "한겨레", "한겨레", "한겨레", "한겨레", "한…
$ title <chr> "'기생충' 아카데미 작품상까지 4관왕…영화사 새로 썼다", "[영상] '기…
$ url <chr> "https://news.naver.com/main/read.nhn?mode=LSD&mid=sec&sid1=104&oid=…
$ id <int> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 2…여백이사라지고 구분숫자가 생긴것을 볼 수 있습니다.
이제 각 댓글들을 단어별로 토큰화 하고 점수를 매겨보도록 하겠습니다.
word_comment <- news_comment %>% unnest_tokens(input = reply, output = word, token = 'words', drop = F)
word_comment %>% select(word, reply) # 토큰화
word_comment <- word_comment %>% left_join(dic, by = 'word') %>% mutate(polarity = ifelse(is.na(polarity), 0, polarity))
word_comment %>% select(word, polarity) # 감정 점수 부여토큰화 하고 점수를 준 결과는 다음과 같습니다.
> word_comment %>% select(word, reply) # 토큰화
# A tibble: 37,718 × 2
word reply
<chr> <chr>
1 정말 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다…
2 우리 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다…
3 집에 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다…
4 좋은 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다…
5 일이 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다…
6 생겨 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다…
7 기쁘고 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다…
8 행복한 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다…
9 것처럼 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다…
10 나의 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다…
# … with 37,708 more rows
>
> word_comment <- word_comment %>% left_join(dic, by = 'word') %>% mutate(polarity = ifelse(is.na(polarity), 0, polarity))
> word_comment %>% select(word, polarity) # 감정 점수 부여
# A tibble: 37,718 × 2
word polarity
<chr> <dbl>
1 정말 0
2 우리 0
3 집에 0
4 좋은 2
5 일이 0
6 생겨 0
7 기쁘고 2
8 행복한 2
9 것처럼 0
10 나의 0
# … with 37,708 more rows위처럼 문장이 단어별로 토큰화되고 각 단어들에 점수가 들어간 것을 볼 수 있습니다.
이제는 문장전체에대한 점수를 주는 코딩을 해보도록 하겠습니다.
score_comment <- word_comment %>% group_by(id, reply) %>% summarise(score = sum(polarity)) %>% ungroup()
score_comment %>% select(score, reply)
# 2-4-1 긍정댓글
score_comment %>% select(score, reply) %>% arrange(-score)
# 2-4-2 부정댓글
score_comment %>% select(score, reply) %>% arrange(score)> score_comment %>% select(score, reply)
# A tibble: 4,140 × 2
score reply
<dbl> <chr>
1 6 정말 우리 집에 좋은 일이 생겨 기쁘고 행복한 것처럼!! 나의 일인 양 행복합니다!…
2 6 와 너무 기쁘다! 이 시국에 정말 내 일같이 기쁘고 감사하다!!! 축하드려요 진심으…
3 4 우리나라의 영화감독분들 그리고 앞으로 그 꿈을 그리는 분들에게 큰 영감을 주시…
4 3 봉준호 감독과 우리나라 대한민국 모두 자랑스럽다. 세계 어디를 가고 우리는 한국…
5 0 노벨상 탄느낌이네요 축하축하 합니다
6 0 기생충 상 받을때 박수 쳤어요.감독상도 기대해요.봉준호 감독 화이팅^^
7 0 대한민국 영화사를 새로 쓰고 계시네요 ㅊㅊㅊ
8 0 저런게 아카데미상 받으면 '태극기 휘날리며'' '광해' '명량''은 전부문 휩쓸어야…
9 0 다시한번 보여주세요 영화관에서 보고싶은디
10 2 대한민국 BTS와함께 봉준호감독님까지 대단하고 한국의 문화에 자긍심을 가지게합…이렇게 문장별로 점수가 측정이 된것을 볼수있습니다.
2보다 숫자가 커질수록 긍정적인 단어가 많이 사용된 댓글임을 알 수 있습니다.
다음은 긍정댓글과, 부정댓글만 따로 추출하여 확인해 보도록 하겠습니다.
> score_comment %>% select(score, reply) %>% arrange(-score)
# A tibble: 4,140 × 2
score reply
<dbl> <chr>
1 11 아니 다른상을 받은것도 충분히 대단하고 굉장하지만 최고의 영예인 작품상을 받은…
2 9 봉준호의 위대한 업적은 진보 영화계의 위대한 업적이고 대한민국의 업적입니다. …
3 7 이 수상소식을 듣고 억수로 기뻐하는 가족이 있을것 같다. SNS를 통해 자기들을 내…
4 7 감사 감사 감사 수상 소감도 3관왕 답네요
> score_comment %>% select(score, reply) %>% arrange(score)
# A tibble: 4,140 × 2
score reply
<dbl> <chr>
1 -7 기생충 영화 한국인 으로써 싫다 대단히 싫다!! 가난한 서민들의 마지막 자존심을 …
2 -6 이 페미민국이 잘 되는 게 아주 싫다. 최악의 나쁜일들과 불운, 불행, 어둡고 암울…
3 -5 특정 인물의 성공을 국가의 부흥으로 연관짓는 것은 미개한 발상이다. 봉준호의 성…
4 -4 좌파들이 나라 망신 다 시킨다..ㅠ 설레발 오지게 치더니..꼴랑 각본상 하나?ㅎㅎ …
다음은 시각적으로 편하게 보기위하여 plot을 생성해 보도록 하겠습니다.
각댓글에서 얼만큼의 긍정어,부정어,중립어구들이 이용되었는지 확인해 보겠습니다.
# 감정 분류
score_comment <- score_comment %>% mutate(sentiment = ifelse(score >= 1, 'pos',
ifelse(score <= -1, 'neg', 'neu')))
# 빈도 비율 구하기
frequency_score <- score_comment %>% count(sentiment) %>% mutate(ratio = n/sum(n)*100)
frequency_score
# 그래프 생성
ggplot(frequency_score, aes(x = sentiment, y = n, fill = sentiment)) +
geom_col() +
geom_text(aes(label = n), vjust = -0.3) +
scale_x_discrete(limits = c('pos', 'neu', 'neg'))위처럼 코드를 입력해주면 다음과 같은 결과가 나옵니다.
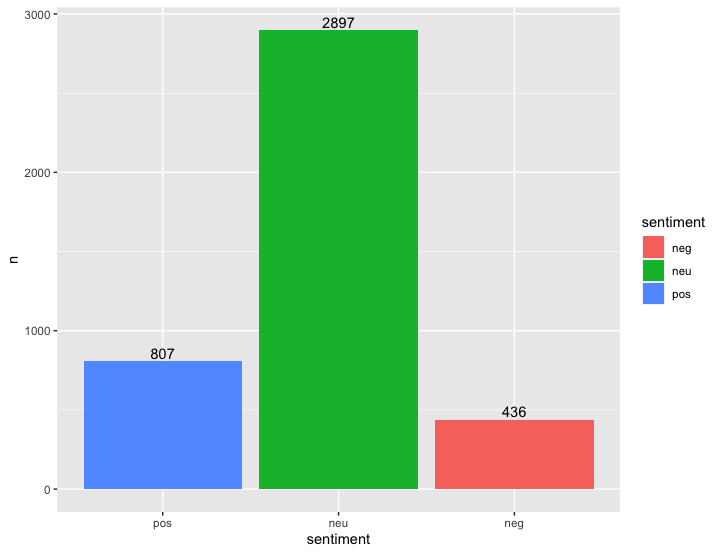
코드를 입력하여 출력되는 결과값보다 훨씬 시각적으로 잘 볼 수 있다는 장점이 있습니다.
댓글들에는 나쁜 댓글보다는 긍정적인 댓글이 더 많이 달렸음을 확인 할 수 있습니다.